
SHARE
Artificial Intelligence in Industry: New Services and Applications
Artificial intelligence (AI) based on artificial vision can capture its surroundings through images provided by a camera. Thanks to it we can decipher what's around us through image recognition, the same way our brain uses sight.
Artificial Intelligence: Machine and Deep Learning
Written by Sergi Palomar
The development of AI is linked to the development and growth of Big Data and IoT. Back in the 50's, AI could not evolve precisely because it did not have large enough volumes of data nor embedded systems with high computing capacity. AI algorithms develop complex understanding processes, information extraction, and data interpretation. Therefore, having a low volume of low-quality data slows down the AI strategy, which is why it is fundamental that the industry considers preparing the data to be processed since it is an essential phase its good results are expected in terms of prediction and precision.
With AI, Industry 4.0 will be able to incorporate the following competitive advantages:
- Time and resource optimization through process automation.
- Help the decision making process with an increase in operation and production efficiency.
- Cost reduction
- Generation of new services and applications
I must highlight the main differences between Machine Learning and Deep Learning for a better adaptation to the final application, from pattern detection to predictive maintenance algorithms to object detection:

Table 1. Differences between Machine Learning and Deep Learning
Deep Learning
When we tag objects in image libraries to train a deep web, we are helping this deep web to ascertain the characteristics of the object to classify. Every layer will take as input the previous layer's output, increasing the complexity and learning from layer to layer.
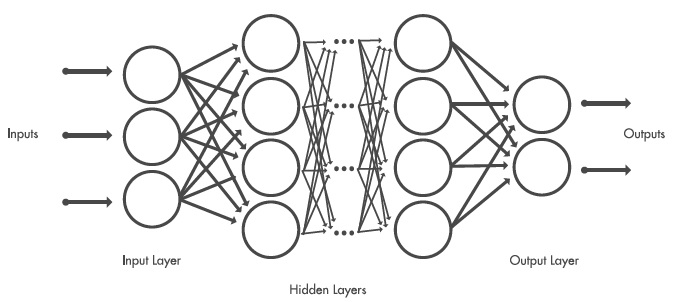
Fig. 1. Examples of neuronal network
Thus, from an input set of images, CNN will learn the required characteristics in its internal layer to be able to tag different objects trained in the output layer.
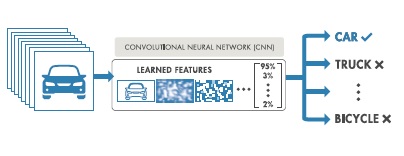
Fig. 2. Tagging and classification
Generally, there is one input layer that collects the images, resizes them and goes on to the next layers, which extract the characteristics. Next layers are convolutional layers, which act as funnels for input images by finding characteristics that will serve as such for the test phase. Later comes the pooling layer, which stores relevant information inside a window, which will allow a better adjustment of characteristics.
Prior to the output layer, we find the rectified linear unit layer, which turns the negative numbers to zero so that the CNN stays mathematically stable. Finally, the last layer collects the high-level characteristics of the images and turns them into categories with tags.
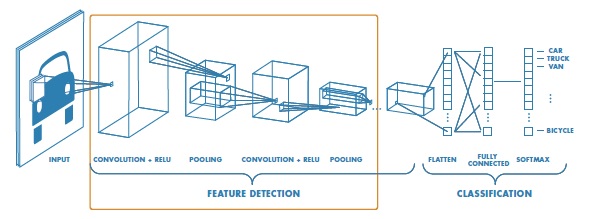
Fig. 3. CNN internal layers
There are currently different solutions to implement neuronal networks. Here are the most relevant ones:
- Tensorflow: it developed by Google Brain Team. It is open source software for numeric computation through graphs.
- Caffe: it is a machine learning framework designed to be used in computer vision or image classification. Caffe is popular thanks to its library of already trained models (Model Zoo) that do not require extra implementation.
- Microsoft CNTK: this is the open source software framework developed by Microsoft. It is very popular in the voice recognition department, although it can also be used for text or images.
- Theano: it is a python library to define, optimize and evaluate mathematical expressions that involve efficient calculations with multidimensional arrays.
- Keras: it is a high-level API for the development of neuronal networks written in Python. It uses other libraries like Tensorflow, CNTK, and Theano. It was developed to make it easier and more agile to develop and experiment with neuronal networks.
These four phases are common to all of them:
- Training: a selection of the neuronal network, dataset preparation, and training.
- Profile: analysis of the neuronal network bandwidth, complexity and execution time.
- Debug: Modify the neuronal network's topology to get a better execution time.
- Implementation: Execute the custom neuronal network over an Edge device.
Applications
In critical infrastructures, video surveillance systems are a key factor both for the internal security of the facilities and for the safety of workers. Due to the proliferation of tools to perfect and trains computer-vision solutions, it is also possible to propose solutions to monitor processes. This makes it possible to match images with other parameters coming from sensors, environmental data, etc., thus enabling more complete solutions for event detection.
As an example of a real application for Industry 4.0, I developed a project last year that I presented at IoT Solutions World Congress (2018) focused on the security of critical infrastructures. The main idea was to automate the restricted access to different areas of the process, automatically detecting people and PPEs (Personal Protective Equipment). This application was aimed for preventive security, with a real-time record of prevention of occupational risks.
The first step is to download images. As examples, here are a safety helmet and a reflective vest. Two different objects will become two different categories, helmet category and vest category, which will be the object to detect both in the training phase and the test phase. 
Fig. 4. Downloaded images for training and test - safety helmet

Fig. 5. Downloaded images for training and test - reflective vest
Convolutional neuronal networks CNN require large datasets and long computing time to complete the training. Some can take 2 to 3 weeks with GPU combinations for the training. Therefore, instead of starting the training from scratch, there is the Transfer Learning method, where a pre-trained network on a different data set adapts to the new problems.
Images must be previously pre-processed and tagged before the training in order to:
- Equalize the images to adjust their contrast
- Resize the images to 227x227 pixels
- Divide the original dataset Dividir el dataset original, in two sub-datasets for training and test, 80% and 20% respectively.
Create the LMBD databases for model assessment. 
Fig. 6. Generating the files train.txt and val.txt
Next, the average image of the training data is calculated, taking out the average image of every input image so that every pixel equals zero. This pre-processing step is usual in supervised machine learning.
Once we have the *.mbd files with the image information for the training, Caffe framework compilation starts in order to verify it works correctly. This training phase will enable us to carry out the prediction phase later. 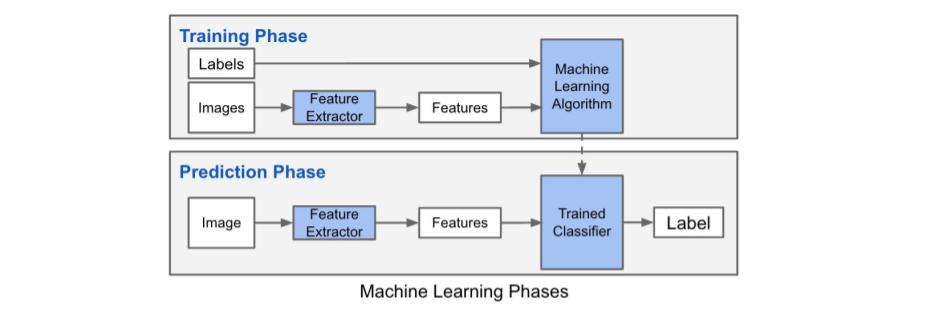
Fig. 7. Training and prediction diagram
This is the neuronal network resulted from the training: 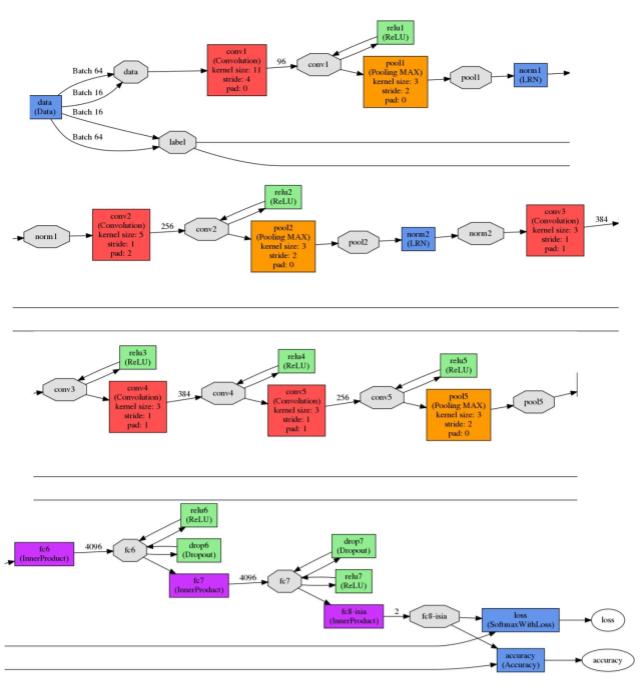
Fig. 8. CNN used in the fine-tuning process
Through the API, which enables the option of interacting with the CNN via Python, it is possible to load the generated graphs and obtain their predictions. In the tests, the prediction on laptops (Core I5, 16GB RAM) is made approximately in 80 minutes, enough time for applications like security and control cameras, etc. 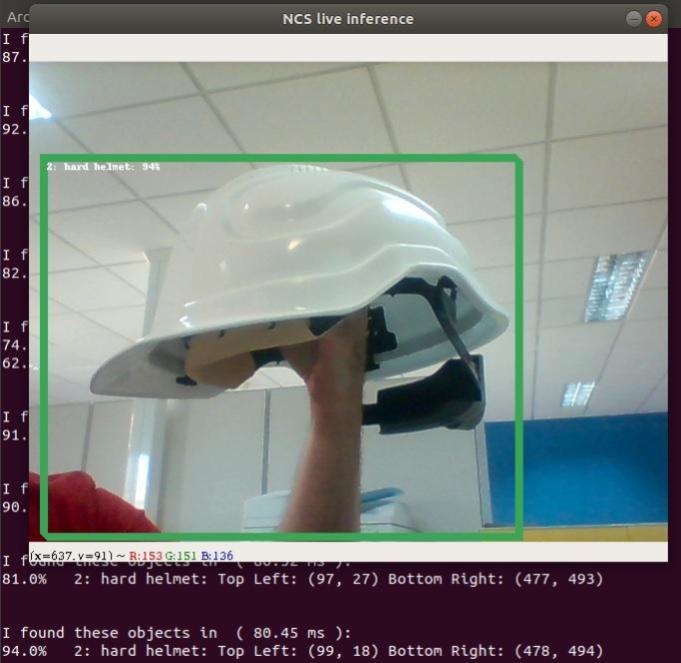
Fig. 9. Detection of the safety helmet
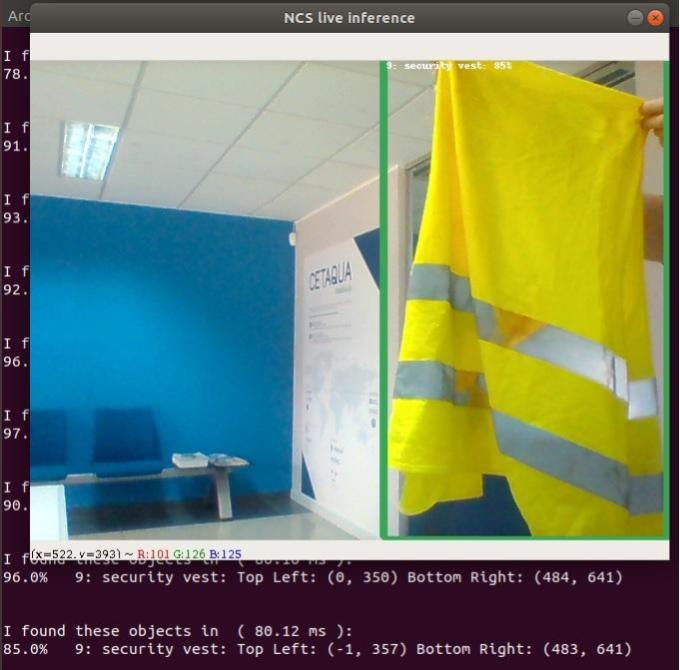
Fig. 10. Detection of the reflective vest
Future of AI in the Industry
Most of the large Spanish corporations have already begun the deployment of AI solutions, mostly pilots and concept tests. A tiny percentage claims to have obtained good results already. Many of them, however, are drifting through the AI sea without a roadmap.
The direct application of object detection through Deep Learning techniques will be a game changer for industrial processes, especially in those where quality or chain production require better factors like plant yield or operational efficiency.  Fig. 12. Example of fruit selection according to quality
Fig. 12. Example of fruit selection according to quality
In other emerging sectors like UAVs and drones, VPU (Visual Processing Unit) integration in their devices enables that, combined with computer vision and deep learning, a drone receives and processes gestural orders like, for instance, getting closer or further, take a picture, activate follow me mode, etc.
With larger UAVs, it will be possible to monitor crops, study the greenery, irrigation status, course of rivers and capacity of reservoirs, border control, etc. Multiple applications that the state of the art will make possible in the coming years when AI will shock us once again until the user gets used to it.
Let us know other applications of artificial intelligence in your industry and explore what ennomotive has to offer in this field. You are also welcome to join our community of engineers to continue learning and competing in challenges.
About the author
In July 2018, ennomotive launched a challenge that looked for a precise and robust solution to detect and monitor dust in industrial environments. 43 engineers from 20 countries accepted the challenge and submitted different solutions.
After a thorough evaluation, the solutions that best met the evaluation criteria were submitted by Manuel Caldas, from Uruguay, Maksym Gaievsky, from Ukraine and Sergi Palomar, from Spain.
Sergi Palomar, Telecommunications and Electronics Engineer and Researcher, Masters in AI and MBA, wrote this article to share his knowledge about the new services and applications of artificial intelligence (AI) in the industry.
References
- Google works with movidius to deploy advanced machine intelligence on mobiles. Biometric Technology Today. 2016, 2 (2016), 12.
- Campos, V., Jou, B., and i Nieto, X. G. From pixels to sentiment: Fine-tuning cnns for visual sentiment prediction. Image and Vision Computing 65 (2017), 15 – 22. Multimodal Sentiment Analysis and Mining in the Wild Image and Vision Computing.
- Gu, J., Wang, Z., Kuen, J., Ma, L., Shahroudy, A., Shuai, B., Liu, T., Wang, X., Wang, G., Cai, J., and Chen, T. Recent advances in convolutional neural networks. Pattern Recognition 77 (2018), 354 – 377.
- Jain, N., Kumar, S., Kumar, A., Shamsolmoali, P., and Zareapoor, M. Hybrid deep neural networks for face emotion recognition. Pattern Recognition Letters (2018).
- Józwiak, L. Advanced mobile and wearable systems. Microprocessors and Microsystems 50 (2017), 202 – 221.
- Li, D., Deng, L., Gupta, B. B., Wang, H., and Choi, C. A novel cnn based security guaranteed image watermarking generation scenario for smart city applications. Information Sciences (2018).
- Lu, K., An, X., Li, J., and He, H. Efficient deep network for vision-based object detection in robotic applications. Neurocomputing 245 (2017), 31 – 45.
- Lu, K., Chen, J., Little, J. J., and He, H. Lightweight convolutional neural networks for player detection and classification. Computer Vision and Image Understanding (2018).
- Sharma, N., Jain, V., and Mishra, A. An analysis of convolutional neural networks for image classification. Procedia Computer Science 132 (2018), 377 – 384. International Conference on Computational Intelligence and Data Science.